Understanding Input/Output tokens vs Latency Tradeoff

created on playgroundai.com; edited
Every few months, openai or anthropic (or <insert LLM API provider>) makes headlines for a new jaw dropping decrease in token costs. While these are impressive feats, cost is only one axis for developers to consider. Accuracy is already well measured (and honestly a wash for many real-world use cases). While building products like MinusX, latency is critical. Relative latency of inputs and outputs is especially important, and affects a lot of design choices (CoT vs multi-turn etc). So, I set about investigating this.
openai vs anthropic API pricing
| provider | openai | anthropic |
|:------------|:-------|:------------------|
| model | gpt-4o | claude-3-5-sonnet |
| input_cost | 5 | 3 |
| output_cost | 15 | 15 |
* All costs $/M tokens (as of Aug 31)
openai: https://openai.com/api/pricing/
anthropic: https://www.anthropic.com/pricing#anthropic-api
The figures above indicate that in gpt-4o, each output token costs 3x as much as one input token. In claude-3.5-sonnet, output is 5x the input token cost.
Predicting Latency
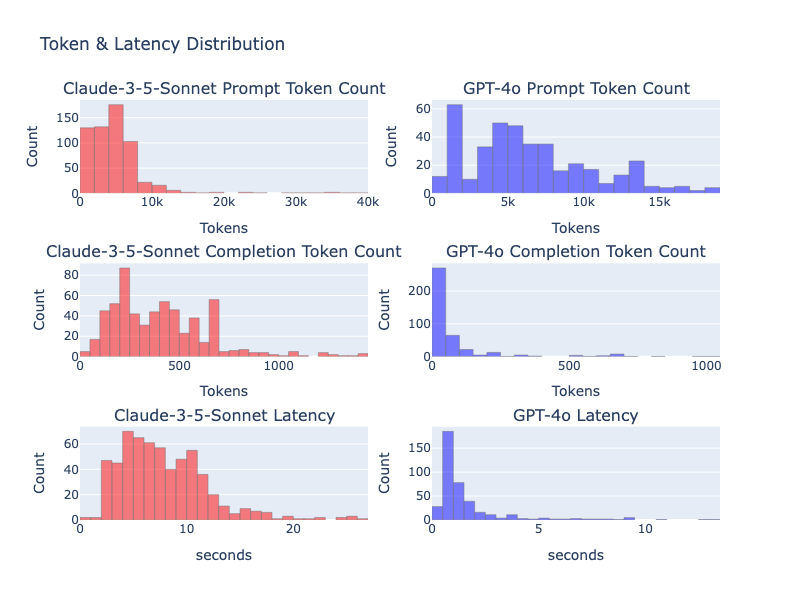
Clearly both the input and output tokens affect the latency differently. Performing a simple regression analysis we get:
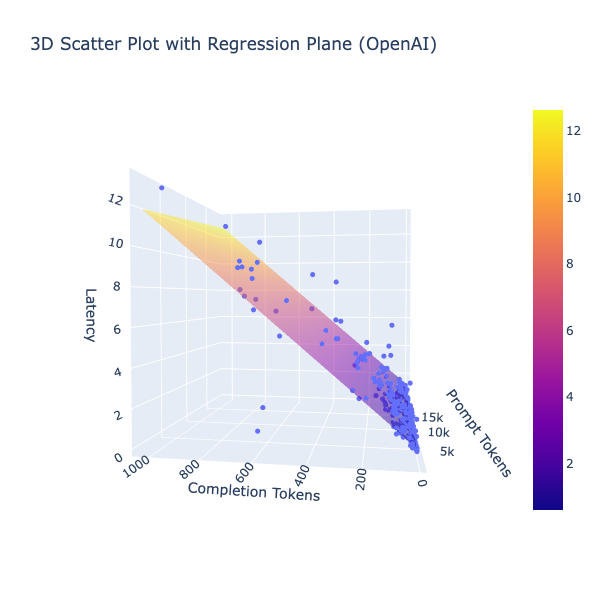
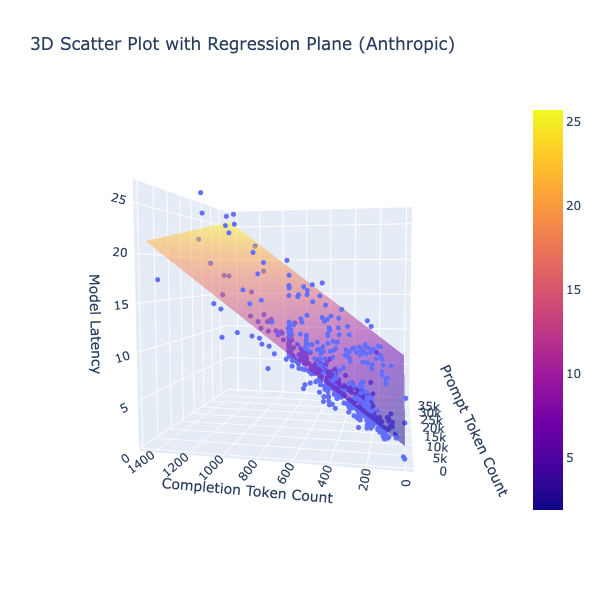
openai vs anthropic regression fits
| provider | openai | anthropic |
|:-----------------------|:---------|:------------------|
| model | gpt-4o | claude-3-5-sonnet |
| a (input_coefficient) | 4.41e-05 | 1.16e-04 |
| b (output_coefficient) | 1.09e-02 | 1.34e-02 |
| c (intercept) | 4.68e-01 | 1.82e+00 |
| r-squared | 0.81 | 0.72 |
| relative latency (b/a) | 247.64 | 115.38 |
* Data for non-streaming tasks only, since we mostly care about tool use
These are decent regression fits! gpt-4o is clearly much faster than claude-3-5-sonnet. But the most interesting takeaway is the input to output token relative latencies. For gpt-4o each output token is ~250x as costly as the input token and for claude-3-5-sonnet, it is ~115x!
Implications
1. Give ~100x more input tokens if it means you can reduce 1 output token
As long as you have good accuracy benchmarks and tests, more context (more state, few shot examples, clearer routines) can be an important lever to reduce latency. Always use custom tags where applicable. "Write code in <Output></Output>" as prompt >>> the model saying "Here is the output code you asked for:". No yapping is a good thing actually.
2. Chain of Thought is not a free lunch
Almost everyone uses the "chain of thought" strategy to make the model reason about it's own thoughts before outputting function calls. Many choose this strategy over "Multi-Turn" because it intuitively feels like outputting all functions in one go should be faster. But this is not the case! Take for example an average use case for MinusX, with 5k input tokens and 2 function calls of 100 output tokens each. Let's say chain of thought would have taken another ~100 tokens. Let's use the gpt-4o model.
Case 1: Chain of Thought
Case 1: Multi-turn
So, the right strategy depends on how much CoT or how many turns it may take to achieve the same accuracy (and the typical input/output token split for your application).
3. Parallel vs Sequential tool call
Given the above calculation, it is clear that most of the latency is from the output tokens and the input tokens are almost a rounding error. So even though parallel tool calls seem like an improvement, sequential calls result in a much snappier experience.
I did this whole analysis on Jupyter using MinusX (in ~8.5 mins). If you use Jupyter (or Metabase) for analytics, give MinusX a try! Here's the notebook and data for this analysis. And here's a realtime video of me using MinusX.