What makes Claude Code so damn good (and how to recreate that magic in your agent)!?

You can clearly see the different Claude Code updates
Claude Code is the most delightful AI agent/workflow I have used so far. Not only does it make targeted edits or vibe coding throwaway tools less annoying, using Claude Code makes me happy. It has enough autonomy to do interesting things, while not inducing a jarring loss of control like some other tools do. Of course most of the heavy lifting is done by the new Claude 4 model (especially interleaved thinking). But I find Claude Code objectively less annoying to use compared to Cursor, or Github Copilot agents even with the same underlying model! What makes it so damn good? If you're reading this and nodding along, I'm going to try and provide some answers.
Note: This is not a blogpost with Claude Code's architecture dump (there are some good ones out there). This blogpost is meant to be a guide for building delightful LLM agents, based on my own experience using and tinkering with Claude Code over the last few months (and all the logs we intercepted and analyzed). You can find prompts and tools in the Appendix section. This post is ~2k words long, so strap in! If you're looking for some quick takeaways, the TL;DR section is a good place to start.
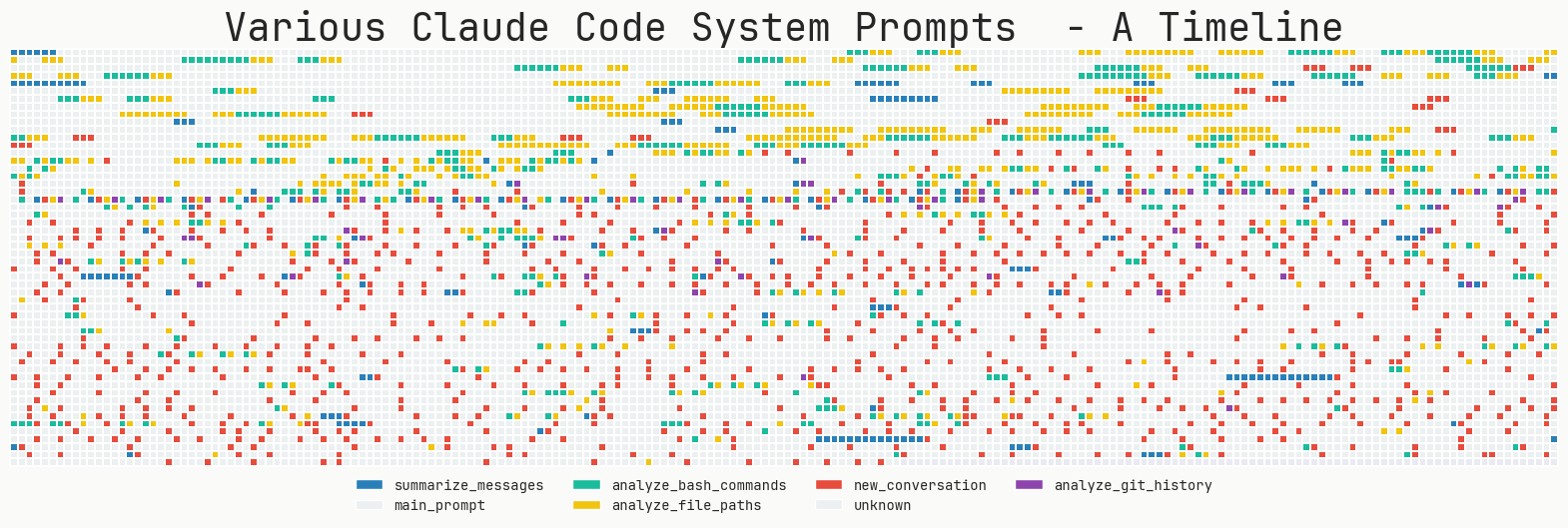
You can clearly see the different Claude Code updates.
Claude Code (CC) feels great to use, because it just simply works. CC has been crafted with a fundamental understanding of what the LLM is good at and what it is terrible at. Its prompts and tools cover for the model's stupidity and help it shine in its wheelhouse. The control loop is extremely simple to follow and trivial to debug.
We started using CC at MinusX as soon as it launched. To look under the hood, Sreejith wrote a logger that intercepts and logs every network request made. The following analysis is from my extensive use over the last couple of months. This post attempts to answer the question - "What makes Claude Code so good, and how can you give a CC-like experience in your own chat-based-LLM agent?" We've incorporated most of these into MinusX already and I'm excited to see you do it too!
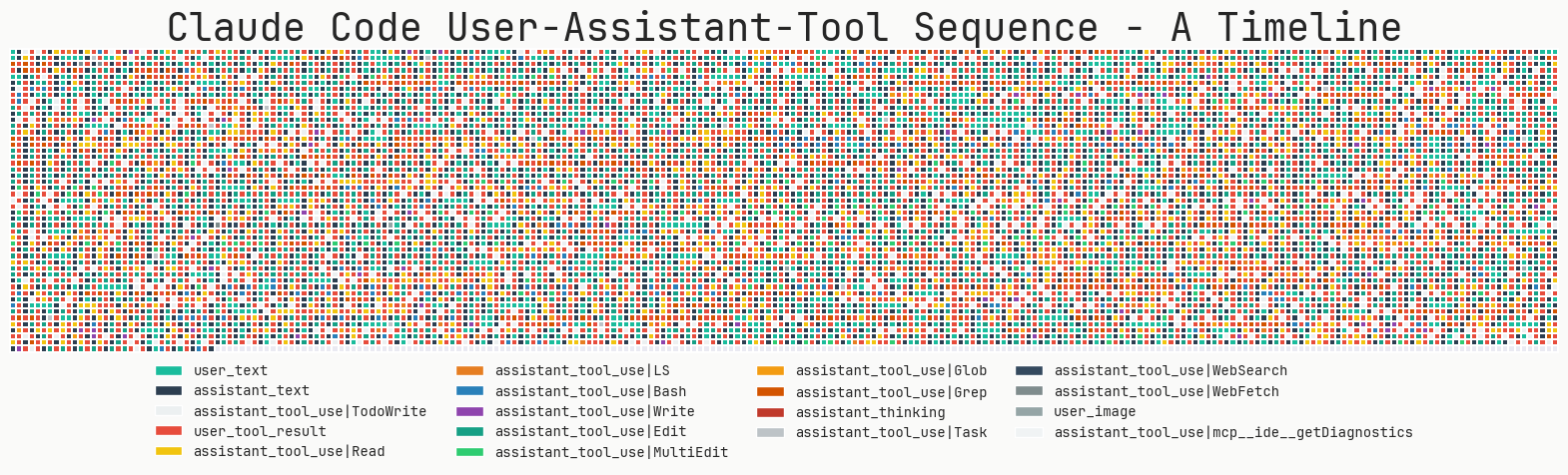
Edit is the most frequent tool, followed by Read and ToDoWrite
How to build a Claude Code like agent: TL;DR
If there is one thing to take away from this, it is this - Keep Things Simple, Dummy. LLMs are terrible enough to debug and evaluate. Any additional complexity you introduce (multi-agents, agent handoffs or complex RAG search algorithms) only makes debugging 10x harder. If such a fragile system works at all, you'll be terrified of making drastic changes to it later. So, keep everything in one file, avoid excessive boilerplate scaffolding and rip it all out at least a couple of times :)
Here are the main takeaways from Claude Code to implement in your own system.
1. Control Loop
- 1.1 Keep one main loop (with max one branch) and one message history
- 1.2 Use a smaller model for all sorts of things. All. The. Frickin. Time.
2. Prompts
- 2.1 Use claude.md pattern to collaborate on and remember user preferences
- 2.2 Use special XML Tags, Markdown, and lots of examples
3. Tools
- 3.1 LLM search >>> RAG based search
- 3.2 How to design good tools? (High vs Low level tools)
- 3.3 Let your agent manage its own todo list
4. Steerability
- 4.1 Tone and style
- 4.2 "PLEASE THIS IS IMPORTANT" is unfortunately still state of the art
- 4.3 Write the algorithm, with heuristics and examples
Claude Code chooses architectural simplicity at every juncture - one main loop, simple search, simple todolist, etc. Resist the urge to over-engineer, build good harness for the model let it cook! Is this end-to-end self-driving all over again? Bitter lesson much?
1. Control Loop Design
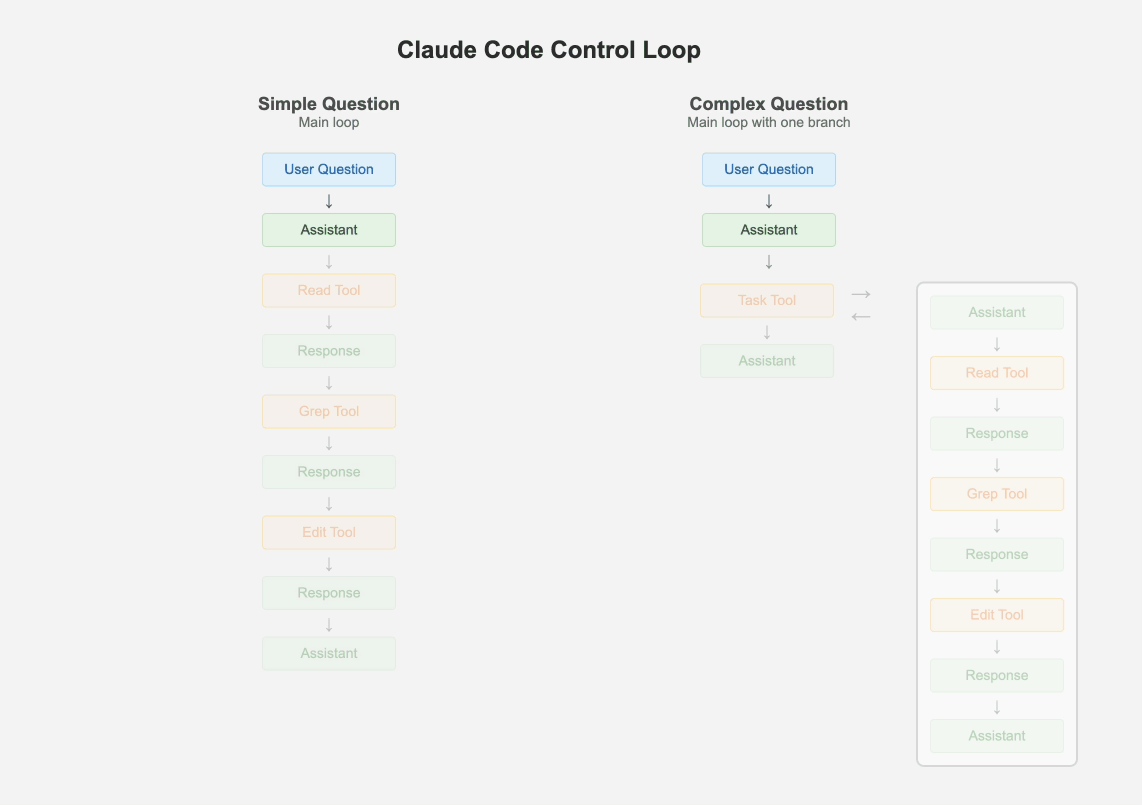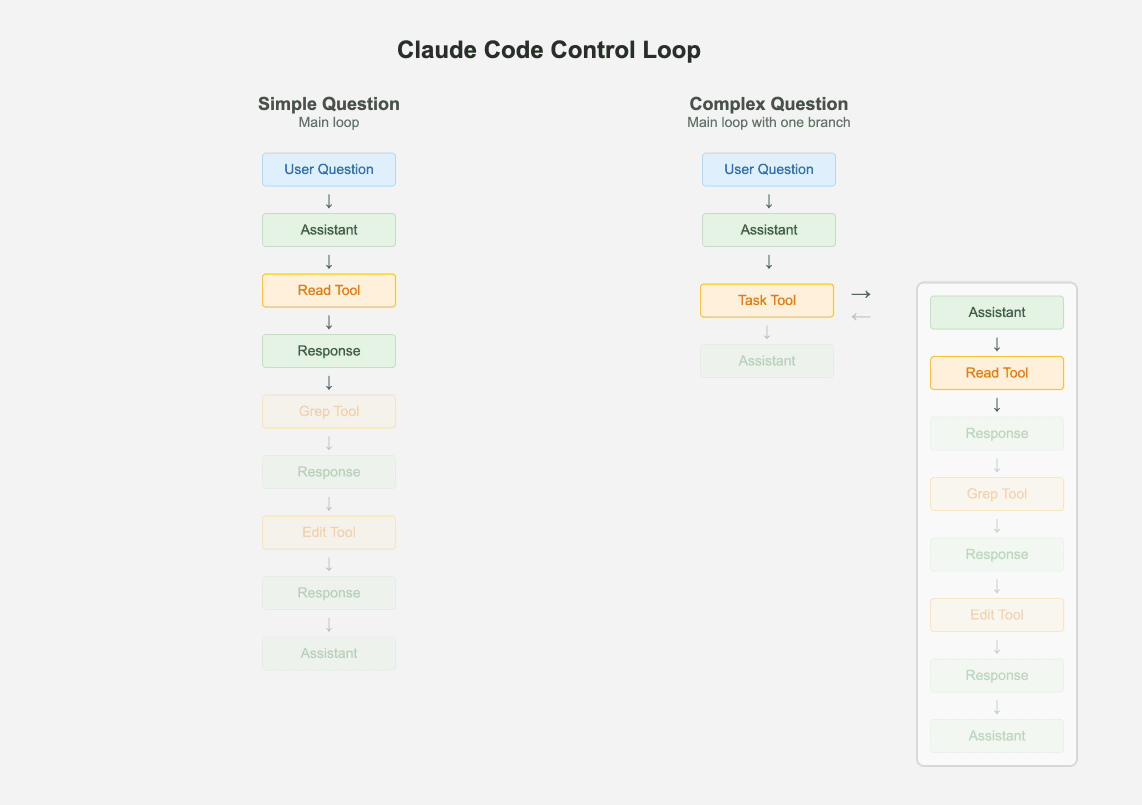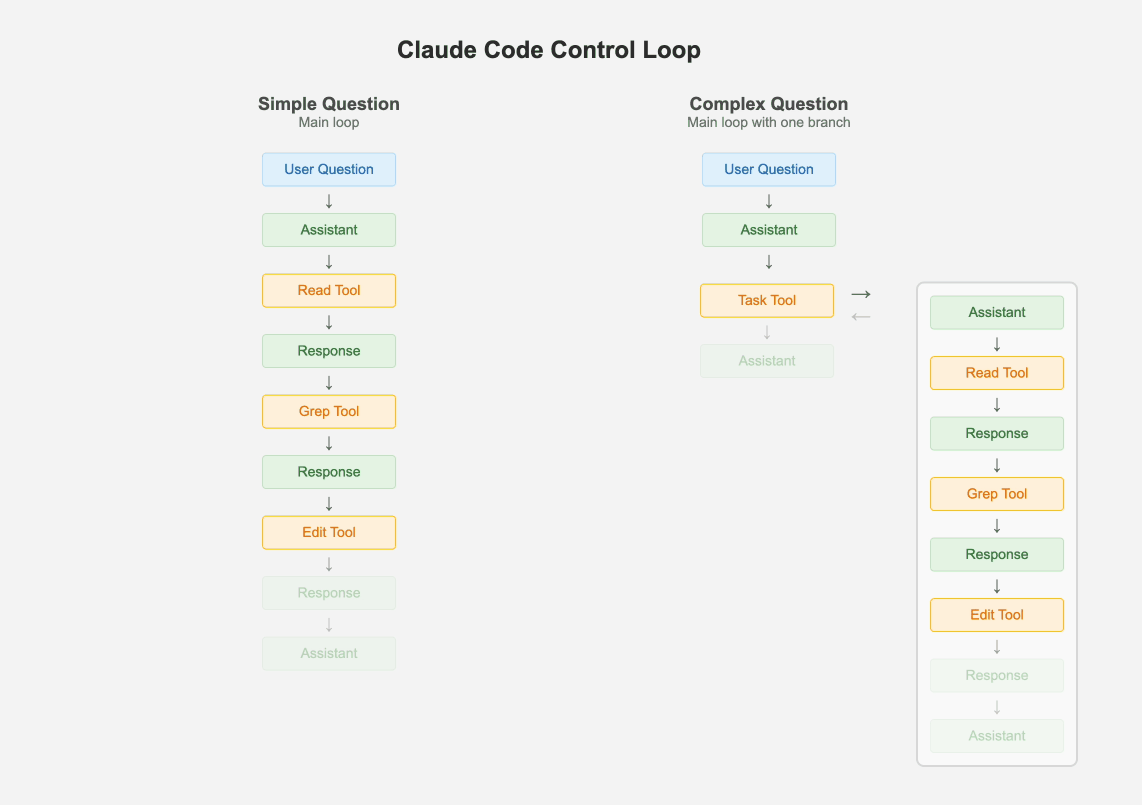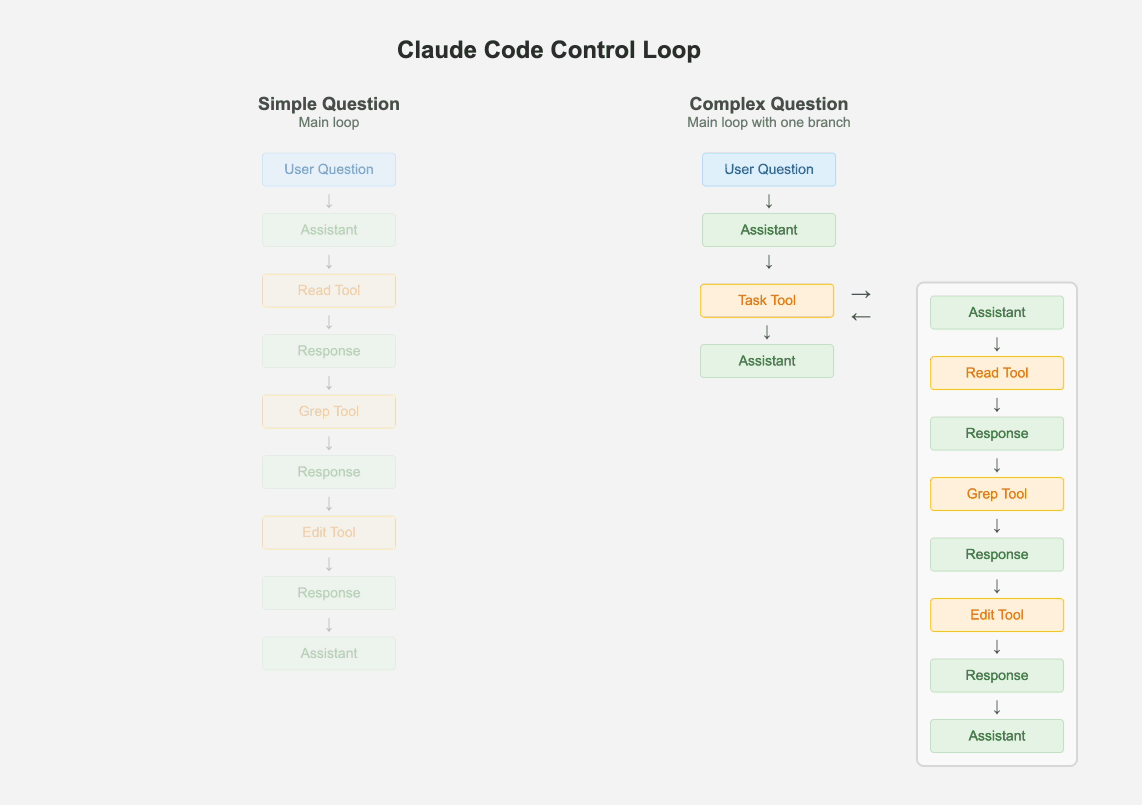
1.1 Keep One Main Loop
Debuggability >>> complicated hand-tuned multi-agent lang-chain-graph-node mishmash.
Despite multi agent systems being all the rage, Claude Code has just one main thread. It uses a few different types of prompts periodically to summarize the git history, to clobber up the message history into one message or to come up with some fun UX elements. But apart from that, it maintains a flat list of messages. An interesting way it handles hierarchical tasks is by spawning itself as a sub-agent without the ability to spawn more sub-agents. There is a maximum of one branch, the result of which is added to the main message history as a "tool response".
If the problem is simple enough, the main loop just handles it via iterative tool calling. But if there are one or more tasks that are complex, the main agent creates clones of itself. The combination of the max-1-branch and the todo list makes sure the agent has the ability to break the problem into sub-problems, but also keep the eye on the final desired outcome.
I highly doubt your app needs a multi-agent system. With every layer of abstraction you make your system harder to debug, and more importantly you deviate from the general-model-improvement trajectory.
1.2 Use a Smaller model for everything
Over 50% of all important LLM calls made by CC are to claude-3-5-haiku. It is used to read large files, parse web pages, process git history and summarize long conversations. It is also used to come up with the one-word processing label - literally for every key stroke! The smaller models are 70-80% cheaper than the standard ones (Sonnet 4, GPT-4.1). Use them liberally!
2. Prompts
Claude Code has extremely elaborate prompts filled with heuristics, examples and IMPORTANT (tch-tch) reminders. The system prompt is ~2800 tokens long, with the Tools taking up a whopping 9400 tokens. The user prompt always contains the claude.md file, which can typically be another 1000-2000 tokens. The system prompt contains sections on tone, style, proactiveness, task management, tool usage policy and doing tasks. It also contains the date, current working directory, platform and OS information and recent commits.
2.1 Use claude.md for collaborating on user context and preferences
One of the major patterns most coding agent creators have settled on is the context file (aka Cursor Rules / claude.md / agent.md). The difference in Claude Code's performance with and without claude.md is night and day. It is a great way for the developers to impart context that cannot be inferred from the codebase and to codify all strict preferences. For example, you can force the LLM to skip some folders, or use specific libraries. CC sends the entire contents of the claude.md with every user request
We recently introduced minusx.md in MinusX which is fast becoming the de-facto context file for our agents to codify user and team preferences.
2.2 Special XML Tags, Markdown, and lots of examples
It is fairly established that XML tags and Markdown are two ways to structure a prompt. CC uses both, extensively. Here are a few notable XML tags in Claude Code:
<system-reminder>: This is used at the end of many prompt sections to remind the LLM of thing it presumably otherwise forgets. Example:
<system-reminder>This is a reminder that your todo list is currently empty. DO NOT mention this to the user explicitly because they are already aware. If you are working on tasks that would benefit from a todo list please use the TodoWrite tool to create one. If not, please feel free to ignore. Again do not mention this message to the user.</system-reminder>
<good-example>,<bad-example>: These are used to codify heuristics. They can be especially useful when there is a fork in the road with multiple seemingly reasonable paths/tool_calls the model can choose. Examples can be used to contrast the cases and make it very clear which path is preferable. Example:
Try to maintain your current working directory throughout the session by using absolute paths and avoiding usage of `cd`. You may use `cd` if the User explicitly requests it.
<good-example>
pytest /foo/bar/tests
</good-example>
<bad-example>
cd /foo/bar && pytest tests
</bad-example>
CC also uses markdown to demarcate clear sections in the system prompt. Example markdown headings include:
- Tone and style
- Proactiveness
- Following conventions
- Code style
- Task Management
- Tool use policy
- Doing Tasks
- Tools
3. Tools
Go read the entire tools prompt - it is a whopping 9400 tokens long!
3.1 LLM search >>> RAG based search
One significant way in which CC deviates from other popular coding agents is in its rejection of RAG. Claude Code searches your code base just as you would, with really complex ripgrep, jq and find commands. Since the LLM understands code really well, it can use sophisticated regex to find pretty much any codeblock it deems relevant. Sometimes it ends up reading whole files with a smaller model.
RAG sounds like a good idea in theory, but it introduces new (and more importantly, hidden) failure modes. What is the similarity function to use? What reranker? How do you chunk the code? What do you do with large JSON or log files? With LLM Search, it just looks at 10 lines of the json file to understand its structure. If it wants, it looks at 10 more lines - just like you would. Most importantly, this is RL learnable - something BigLabs are already working on. The model does most of the heavy lifting - as it should, dramatically reducing the number of moving parts in the agent. Also, having two complicated, intelligent systems wired this way is just ugly. I was recently kidding with a friend saying this is the Camera vs Lidar of the LLM era and I'm only half joking.
3.2 How to design good tools? (Low level vs High level tools)
This question keeps anyone who is building an LLM agent up at night. Should you give the model generic tasks (like meaningful actions) or should it be low level (like type and click and bash)? The answer is that it depends (and you should use both).
Claude Code has low level (Bash, Read, Write), medium level (Edit, Grep, Glob) and high level tools (Task, WebFetch, exit_plan_mode). CC can use bash, so why give a separate Grep tool? The real trade-off here is in how often you expect your agent to use the tool vs accuracy of the agent in using the tool. CC uses grep and glob so frequently that it makes sense to make separate tools out of them, but at the same time, it can also write generic bash commands for special scenarios.
Similarly, there are even higher level tools like WebFetch or 'mcp__ide__getDiagnostics' that are extremely deterministic in what they do. This saves the LLM from having to do multiple low level clicking and typing and keeps it on track. Help the poor model out, will ya!? Tool descriptions have elaborate prompts with plenty of examples. The system prompt has information about ‘when to use a tool' or how to choose between two tools that can do the same task.
Tools in Claude Code:
3.3 Let the agent manage a todo list
There are many reasons why this is a good idea. Context rot is a common problem in long-running LLM agents. They enthusiastically start out tackling a difficult problem, but over time lose their way and devolve into garbage. There are a few ways current agent designs tackle this. Many agents have experimented with explicit todos (one model generates todos, another model implements them) or with Multi-agent handoff + verification (PRD/PM agent -> implementer agent -> QA agent)
We already know multi-agent handoff is not a good idea, for many many reasons. CC uses an explicit todo list, but one that the model maintains. This keeps the LLM on track (it has been heavily prompted to refer to the todo list frequently), while at the same time giving the model the flexibility to course correct mid-way in an implementation. This also effectively leverages the model's interleaved thinking abilities to either reject or insert new todo items on the fly.
4. Steerability
4.1 Tone and Style
CC explicitly attempts to control the aesthetic behavior of the agent. There are sections in the system prompt around tone, style and proactiveness - full of instructions and examples. This is why Claude Code “feels” tasteful in its comments and eagerness. I recommend just copying large sections of this into your app as is.
# Some examples of tone and style
- IMPORTANT: You should NOT answer with unnecessary preamble or postamble (such as explaining your code or summarizing your action), unless the user asks you to.
Do not add additional code explanation summary unless requested by the user.
- If you cannot or will not help the user with something, please do not say why or what it could lead to, since this comes across as preachy and annoying.
- Only use emojis if the user explicitly requests it. Avoid using emojis in all communication unless asked.
4.2 "THIS IS IMPORTANT" is still State of the Art
Unfortunately CC is no better when it comes to asking the model to not do something. IMPORTANT, VERY IMPORTANT, NEVER and ALWAYS seem to be the best way to steer the model away from landmines. I expect the models to get more steerable in the future and avoid this ugliness. But for now, CC uses this liberally, and so should you. Some examples:
- IMPORTANT: DO NOT ADD ***ANY*** COMMENTS unless asked
- VERY IMPORTANT: You MUST avoid using search commands like `find` and `grep`. Instead use Grep, Glob, or Task to search. You MUST avoid read tools like `cat`, `head`, `tail`, and `ls`, and use Read and LS to read files.\n - If you _still_ need to run `grep`, STOP. ALWAYS USE ripgrep at `rg` first
- IMPORTANT: You must NEVER generate or guess URLs for the user unless you are confident that the URLs are for helping the user with programming. You may use URLs provided by the user in their messages or local files.
4.3 Write the Algorithm (with heuristics and examples)
It is extremely important to identify the most important task the LLM needs to perform and write out the algorithm for it. Try to role-play as the LLM and work through examples, identify all the decision points and write them explicitly. It helps if this is in the form of a flow-chart. This helps structure the decision making and aids the LLM in following instructions. One thing to definitely avoid is a big soup of Dos and Don'ts. They are harder to keep track, and keep mutually exclusive. If your prompt is several thousand tokens long, you will inadvertently have conflicting Dos and Don'ts. The LLM becomes extremely fragile in this case and it becomes impossible to incorporate new use cases.
Task Management, Doing Tasks and Tool Usage Policy sections in Claude Code's system prompt clearly walk through the algorithm to follow. This is also the section to add lots of heuristics and examples of various scenarios the LLM might encounter.
Bonus: Why pay attention to BigLab prompts?
A lot of the effort in steering LLMs is trying to reverse engineer their post-training / RLHF data distribution. Should you use JSON or XML? Should the tool descriptions be in the system prompt or just in tools? What about your app's current state? It helps to see what they do in their own apps and use it to inform yours. Claude Code design is very opinionated and it helps to use that in forming your own.
Conclusion
The main takeaway, again, is to keep things simple. Extreme scaffolding frameworks will hurt more than help you. Claude Code really made me believe that an "agent" can be simple and yet extremely powerful. We've incorporated a bunch of these lessons into MinusX, and are continuing to incorporate more.
If you're interested in Claude-Codifying your own LLM agent, I'd love to chat - ping me on twitter! If you want trainable Claude Code like data agents for your Metabase, check out MinusX or set up a demo with me. Happy (Claude) Coding!